华为暑期实习java后端开发
==和equals的区别
- 对于==,如果作用于基本数据类型的变量,则直接比较其存储的”值”是否相等;如果作用于引用类型的变量,则比较的是所指向的对象的地址。
- 对于equals方法,注意:equals方法不能作用于基本数据类型的变量。如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。
equals相同,hashcode相同吗?
- 假如这个类没有重写equals方法,equals相同,hashcode一定相同。
- 如果重写了equals方法,没有重写hashcode方法,equals相同,hashcode不一定相同。
创建线程的方式
- 继承Thread类。
- 实现Runnable接口。
callable和runnable的区别
- 相同点
- 两者都是接口;
- 两者都可用来编写多线程程序;
- 两者都需要调用Thread.start()启动线程;
- 不同点
- 实现Callable接口的任务线程能返回执行结果;而实现Runnable接口的任务线程不能返回结果;
- Callable接口的call()方法允许抛出异常;而Runnable接口的run()方法的异常只能在内部消化,不能继续上抛。
线程池参数
- int corePoolSize:线程池的核心线程数量;
- int maximumPoolSize:线程池的最大线程数;
- long keepAliveTime:当线程数大于核心线程数时,多余的空闲线程存活的最长时间;
- TimeUnit unit:时间单位;
- BlockingQueue workQueue:任务队列,用来储存等待执行任务的队列;
- ThreadFactory threadFactory:线程工厂,用来创建线程,一般默认即可;
- RejectedExecutionHandler handler:拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务;
讲下乐观锁,乐观锁提交时怎么判断是否冲突
- 总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。
- 使用版本号机制和CAS算法实现。
- Java并发包下面的原子类使用乐观锁来实现的。
什么是版本号机制
一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
什么是CAS算法
- compare and swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步。
- CAS算法涉及到三个操作数:
- 需要读写的内存值 V
- 进行比较的值 A
- 拟写入的新值 B
- 当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试。
讲下悲观锁
- 总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。
- Java中的synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
怎么避免死锁
- 正确的顺序获得锁:如果必须获取多个锁,就要考虑不同线程获取锁的顺序。
- 超时放弃:当线程获取锁超时了则放弃,这样就避免了出现死锁获取的情况。
索引,哪些字段可以加索引,索引缺点
- 索引用于快速找出在某个列中有一特定值的行。
- 适合建立索引的字段:
- 经常需要搜索的列
- 作为主键的列
- 经常用在连接的列,主要是外键
- 经常需要根据范围进行搜索的列
- 经常需要排序的列
- 经常使用在where子句中的列
- 索引的缺点:
- 创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加。
- 索引也需要占空间,我们知道数据表中的数据也会有最大上限设置的,如果我们有大量的索引,索引文件可能会比数据文件更快达到上限值。
- 当对表中的数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度。
final关键字修饰类,方法以及变量的特点
- 修饰类,类不能被继承。
- 修饰变量,变量就变成了常量,只能被赋值一次。
- 修饰方法,方法不能被重写。
父类子类构造函数,静态代码段,构造代码段加载顺序
- 父类的静态代码段
- 子类的静态代码段
- 父类的构造代码段
- 父类的构造函数
- 子类的构造代码段
- 子类的构造函数
讲一下二叉查找树和平衡二叉树。二叉查找树的缺点,平衡二叉树缺点
- 二叉查找树的特点就是左子树的节点值比父节点小,右子树的节点值比父节点大。当插入的数据有序时,二叉查找树会退化为一条链表,查找的时间复杂度变为O(n)。
- 平衡二叉树具有二叉查找树的全部特性,每个节点的左子树和右子树的高度差至多等于1。每次进行插入、删除节点的时候,几乎都会破快平衡树的规则,需要通过左旋和右旋进行调整,使它再次成为一颗符合要求的平衡树。
Linux查看端口是否被占用命令
netstat -tnlp | grep 端口号
Spring bean生命周期
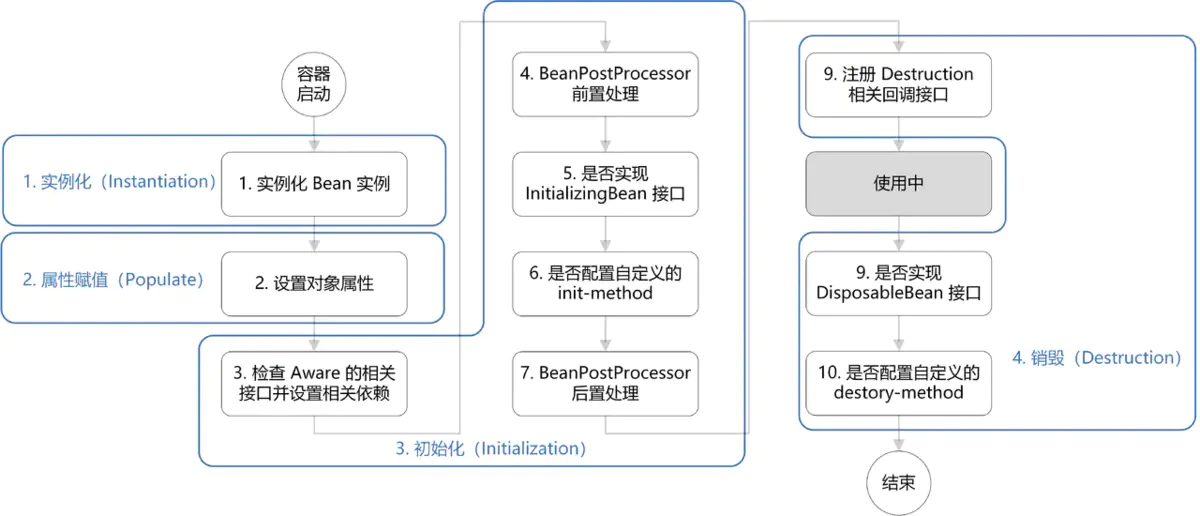
- 实例化(Instantiation):实例化一个bean对象。
- 属性赋值(Populate):为bean设置相关属性和依赖。
- 初始化(Initialization):有Aware接口的依赖注入、BeanPostProcessor在初始化前后的处理以及InitializingBean和init-method的初始化操作。
- 销毁(Destruction):有注册相关销毁回调接口,最后通过DisposableBean和distory-method进行销毁。
redis和本地缓存区别,为什么用redis不用本地缓存?
- 缓存分为本地缓存和分布式缓存。以Java为例,使用自带的Map实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着jvm的销毁而结束,缓存不具有一致性;使用redis的称为分布式缓存,缓存具有一致性。
- Redis可以用几十G内存来做缓存,Map不行,一般JVM也就分几个G数据就够大了。
- Redis的缓存可以持久化,Map是内存对象,程序一重启数据就没了。
- Redis可以实现分布式的缓存,Map只能存在创建它的程序中。
- Redis可以处理每秒百万级的并发,是专业的缓存服务,Map只是一个普通的对象。
- Redis缓存有过期机制,Map本身无此功能。
参考